
%matplotlib inline import numpy as np import torch torch.set_printoptions(edgeitems=2, threshold=75)
In [2]:
t_c=[0.5,14.0,15.0,28.0,11.0,8.0,3.0,-4.0,6.0,13.0,21.0] t_u=[35.7,55.9,58.2,81.9,56.3,48.9,33.9,21.8,48.4,60.4,68.4]
In [3]:
t_c=torch.tensor(t_c) t_u=torch.tensor(t_u)
In [4]:
t_u
Out[4]:
tensor([35.7000, 55.9000, 58.2000, 81.9000, 56.3000, 48.9000, 33.9000, 21.8000,
48.4000, 60.4000, 68.4000])
In [5]:
import matplotlib.pyplot as plt fig=plt.figure() plt.scatter(t_c,t_u,c='b',edgecolors="r")
Out[5]:
<matplotlib.collections.PathCollection at 0x226b216e090>
In [6]:
def model(t_u,w,b):
return t_u*w+b
In [7]:
def loss_fn(t_p,t_c):
squared_diffs=(t_p-t_c)**2
return squared_diffs.mean()
In [8]:
w=torch.ones(()) b=torch.zeros(()) t_p=model(t_u,w,b) t_p
Out[8]:
tensor([35.7000, 55.9000, 58.2000, 81.9000, 56.3000, 48.9000, 33.9000, 21.8000,
48.4000, 60.4000, 68.4000])
In [9]:
w
Out[9]:
tensor(1.)
In [10]:
loss=loss_fn(t_p,t_c) loss
Out[10]:
tensor(1763.8848)
In [11]:
w=torch.zeros(()) b=torch.zeros(()) t_p=model(t_u,w,b) t_p
Out[11]:
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [12]:
loss=loss_fn(t_p,t_c) loss # 通过损失函数来调整参数
Out[12]:
tensor(187.3864)
广播机制
In [14]:
x=torch.ones(()) y=torch.ones(3,1) z=torch.ones(1,3) a=torch.ones(2,1,1)
In [15]:
print("x*y",(x*y).shape)
x*y torch.Size([3, 1])
In [16]:
print("y*z",(y*z).shape)
y*z torch.Size([3, 3])
In [17]:
print("y*z*a",(y*z*a).shape)
y*z*a torch.Size([2, 3, 3])
In [18]:
x=torch.ones(5,2,4,1) y=torch.ones(3,1,1) #有数维度太高无法理解广播机制就起不了作用
梯度
编写梯度代码
In [20]:
def dloss_fn(t_p,t_c):
dsq_diffs=2*(t_p-t_c)/t_p.size(0)
return dsq_diffs
def dmodel_dw(t_u,w,b):
return t_u
def dmodel_db(t_u,w,b):
return 1.0
In [21]:
def grad_fn(t_u,t_c,t_p,w,b):
dloss_dtp=dloss_fn(t_p,t_c)
dloss_dw=dloss_dtp*dmodel_dw(t_u,w,b)
dloss_db=dloss_dtp*dmodel_db(t_u,w,b)
return torch.stack([dloss_dw.sum(),dloss_db.sum()])
In [22]:
delta=0.1 loss_rate_of_change_w=(loss_fn(model(t_u,w+delta,b),t_c))-(loss_fn(model(t_u,w-delta,b),t_c))/(2.0*delta) learning_rate=1e-2 w=w-learning_rate*loss_rate_of_change_w loss_rate_of_change_b=(loss_fn(model(t_u, w,b+delta),t_c)-loss_fn(model(t_u, w, b-delta),t_c))/(2.0*delta) b=b-learning_rate*loss_rate_of_change_b
In [23]:
def training_loop(n_epochs,learning_rate,params,t_u,t_c):
for epoch in range(1,n_epochs+1):
w,b=params
t_p=model(t_u,w,b)
loss=loss_fn(t_p,t_c)
grad=grad_fn(t_u,t_c,t_p,w,b)
params=params-learning_rate*grad
print("Epoch %d,loss %f" % (epoch,float(loss)))
return params
In [24]:
t_un=0.1*t_u params=training_loop(n_epochs=20000,learning_rate=1e-2,params=torch.tensor([10,0.0]),t_u=t_un,t_c=t_c) print(params)
Epoch 19994,loss 2.927645 Epoch 19995,loss 2.927645 Epoch 19996,loss 2.927645 Epoch 19997,loss 2.927645 Epoch 19998,loss 2.927645 Epoch 19999,loss 2.927645 Epoch 20000,loss 2.927645 tensor([ 5.3676, -17.3042])
In [25]:
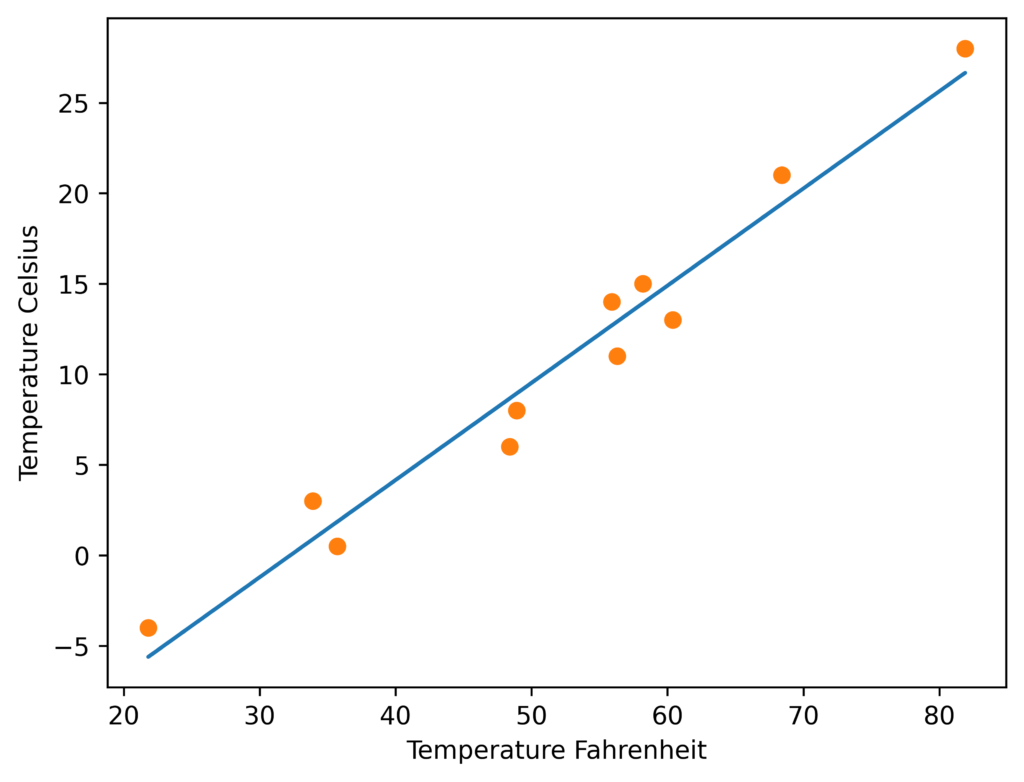
%matplotlib inline
from matplotlib import pyplot as plt
t_p=model(t_un,*params)
fig=plt.figure(dpi=600)
plt.xlabel("Temperature Fahrenheit")
plt.ylabel("Temperature Celsius")
plt.plot(t_u.numpy(),t_p.detach().numpy())
plt.plot(t_u.numpy(),t_c.numpy(),"o")
plt.savefig("temp_unknow_plot.png")
PyTorch自动梯度计算
自动求导
In [28]:
t_c=torch.tensor([0.5,14.0,15.0,28.0,11.0,8.0,3.0,-4.0,6.0,13.0,21.0])
t_u=torch.tensor([35.7,55.9,58.2,81.9,56.3,48.9,33.9,21.8,48.4,60.4,68.4])
# 定义函数
def model(t_u,w,b):
return t_u*w+b
# 算方差
def loss_fn(t_p,t_c):
squared_diffs=(t_p-t_c)**2
return squared_diffs.mean()
# 唯一改变
params=torch.tensor([1.0,0.0],requires_grad=True)
# 反向传播
loss=loss_fn(model(t_u,*params),t_c)
loss.backward()
# 输出params的梯度看看
params.grad
Out[28]:
tensor([4517.2969, 82.6000])
In [29]:
def training_loop(n_epochs,learning_rate,params,t_u,t_c):
for epoch in range(1,n_epochs+1):
if params[0].grad is None:
params.grad.zero_()
t_p=model(t_u,*params)
loss=loss_fn(t_p,t_c)
loss.backward()
with torch.no_grad():
params-=learning_rate*params.grad
if epoch%500==0:
print("Epoch %d,loss %f" % (epoch,float(loss)))
return params
In [30]:
t_un=0.1*t_u params=training_loop(n_epochs=3000,learning_rate=1e-2,params=params,t_u=t_un,t_c=t_c) print(params)
C:\Users\tanhaowen\AppData\Local\Temp\ipykernel_13452\3767616033.py:3: UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (Triggered internally at C:\cb\pytorch_1000000000000\work\build\aten\src\ATen/core/TensorBody.h:494.) if params[0].grad is None:
Epoch 500,loss 7.860115 Epoch 1000,loss 3.828538 Epoch 1500,loss 3.092191 Epoch 2000,loss 2.957698 Epoch 2500,loss 2.933134 Epoch 3000,loss 2.928648 tensor([ 5.3489, -17.1980], requires_grad=True)
PyTorch的优化器
In [32]:
import torch.optim as optim params=torch.tensor([1.0,0.0],requires_grad=True) learning_rate=1e-5 optimizer=optim.SGD([params],lr=learning_rate) t_p=model(t_u,*params) loss=loss_fn(t_p,t_c) loss.backward() optimizer.step() params
Out[32]:
tensor([ 9.5483e-01, -8.2600e-04], requires_grad=True)
In [33]:
def training_loop(n_epochs,optimizer,params,t_u,t_c):
for epoch in range(1,n_epochs+1):
t_p=model(t_u,*params)
loss=loss_fn(t_p,t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch%500==0:
print("Epoch %d,loss %f" % (epoch,float(loss)))
return params
In [34]:
params=torch.tensor([1.0,0.0],requires_grad=True) learning_rate=1e-2 optimizer=optim.SGD([params],lr=learning_rate) training_loop(n_epochs=1000,optimizer=optimizer,params=params,t_u=t_un,t_c=t_c)
Epoch 500,loss 7.860115 Epoch 1000,loss 3.828538
Out[34]:
tensor([ 4.8021, -14.1031], requires_grad=True)
In [35]:
# 激活函数 %matplotlib inline import numpy import torch import torch.optim as optim torch.set_printoptions(edgeitems=2,linewidth=75) t_c=[0.5,14.0,15.0,28.0,11.0,8.0,3.0,-4.0,6.0,13.0,21.0] t_u=[35.7,55.9,58.2,81.9,56.3,48.9,33.9,21.8,48.4,60.4,68.4] t_c=torch.tensor(t_c).unsqueeze(1) t_u=torch.tensor(t_u).unsqueeze(1)
In [36]:
t_u.shape
Out[36]:
torch.Size([11, 1])
In [37]:
n_samples=t_u.shape[0] n_val=int(0.2*n_samples) shuffled_indices=torch.randperm(n_samples) train_indices=shuffled_indices[:-n_val] val_indices=shuffled_indices[-n_val:] t_u_train=t_u[train_indices] t_c_train=t_c[train_indices] t_u_val=t_u[val_indices] t_c_val=t_c[val_indices] t_un_train=0.1*t_u_train t_un_val=0.1*t_u_val
In [38]:
import torch.nn as nn linear_model=nn.Linear(1,1) linear_model(t_un_val)
Out[38]:
tensor([[2.3831],
[2.0567]], grad_fn=<AddmmBackward0>)
In [39]:
linear_model.weight
Out[39]:
Parameter containing: tensor([[0.3331]], requires_grad=True)
In [40]:
linear_model.bias
Out[40]:
Parameter containing: tensor([0.4445], requires_grad=True)
In [41]:
x=torch.ones(10,1) linear_model(x)
Out[41]:
tensor([[0.7776],
[0.7776],
[0.7776],
[0.7776],
[0.7776],
[0.7776],
[0.7776],
[0.7776],
[0.7776],
[0.7776]], grad_fn=<AddmmBackward0>)
In [42]:
optimizer=optim.SGD(
linear_model.parameters(),
lr=1e-2
)
list(linear_model.parameters())
Out[42]:
[Parameter containing: tensor([[0.3331]], requires_grad=True), Parameter containing: tensor([0.4445], requires_grad=True)]
In [43]:
def train_loop(n_epochs,optimizer,model,loss_fn,t_u_train,t_u_val,t_c_train,t_c_val):
for epoch in range(1,n_epochs+1):
t_p_train=model(t_u_train)
loss_train=loss_fn(t_p_train,t_c_train)
t_p_val=model(t_u_val)
loss_val=loss_fn(t_p_train,t_c_train)
optimizer.zero_grad()
loss_train.backward()
optimizer.step()
if epoch==1 or epoch %1000==0:
print(f"Epoch {epoch},Training loss loss {loss_train.item():.4f},"f"Validation loss {loss_val.item():.4f}")
In [44]:
def loss_fn(t_p,t_c):
squard_diffs=(t_p-t_c)**2
return squard_diffs.mean()
linear_model=nn.Linear(1,1)
optimizer=optim.SGD(linear_model.parameters(),lr=1e-2)
train_loop(
n_epochs=3000,
optimizer=optimizer,
model=linear_model,
loss_fn=loss_fn,
t_u_train=t_u_train,
t_u_val=t_u_val,
t_c_train=t_c_train,
t_c_val=t_c_val,
)
发表回复